Stabilizing and Re-Architecting Amzigo’s Multi-Tenant Amazon Analytics Platform
“We came to Parallel Loop highly frustrated after our previous development agency left us with a fragile system that crashed daily. They stabilized our pipelines instantly, removed expensive scrapers, and rebuilt our entire SaaS in just 10 weeks. Now we can finally scale.”
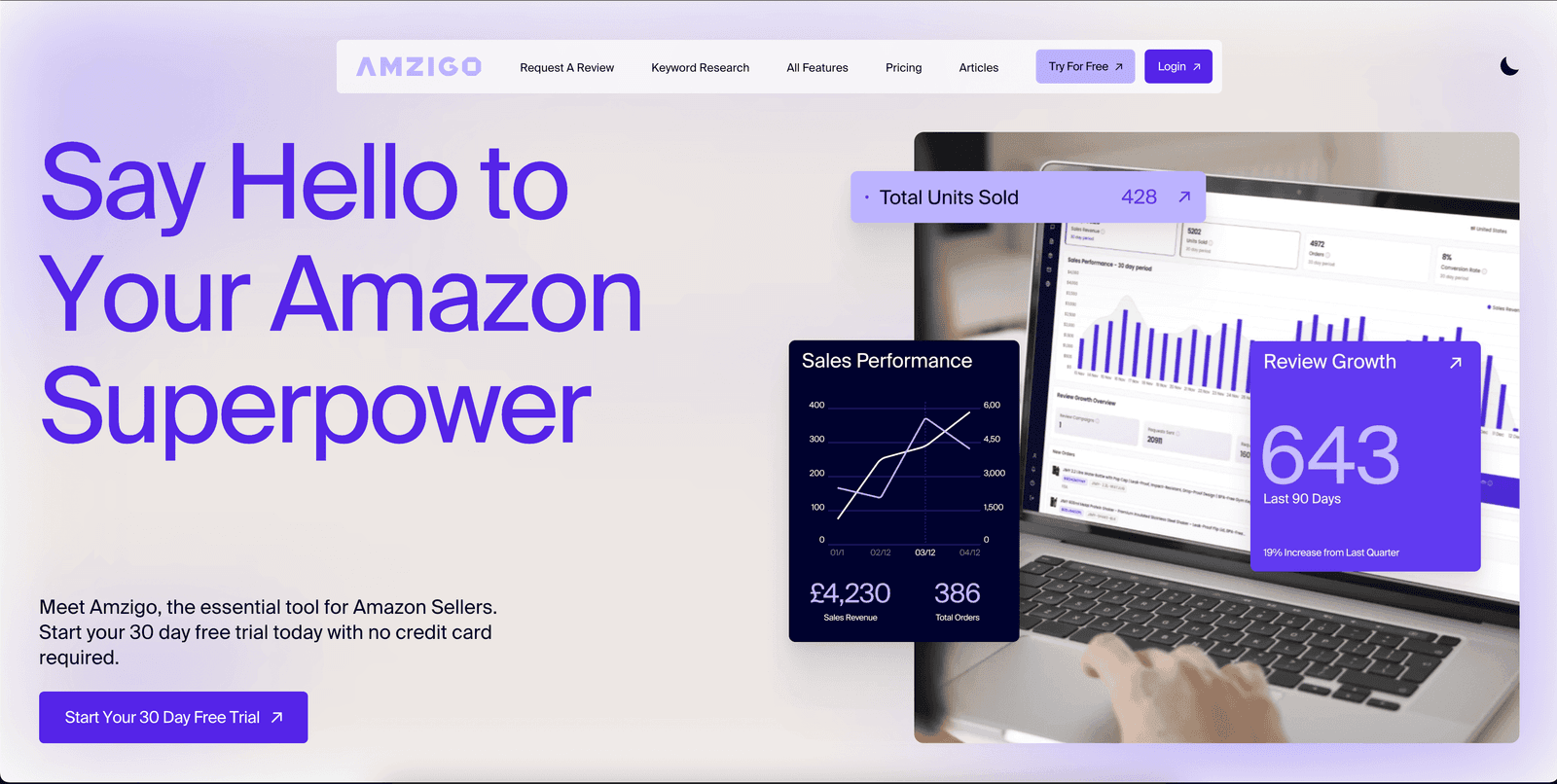
Amzigo is a comprehensive multi-tenant intelligence suite that empowers Amazon sellers by automating review requests, providing real-time product analysis, hosting a centralized Mail Response Centre, and aggregating financial metrics into a profit and loss dashboard.
The Architectural Bottleneck
Parallel Loop stepped in to rescue a critical architectural breakdownafter the client's previous development agency delivered an unstable, unmanageable application. The legacy stack relied on Bubble.io for the user interface and main database, offloading heavy processing tasks to an AWS serverless microservices setup. While a hybrid Bubble-AWS serverless concept appeared theoretically sound, the execution was highly flawed: AWS SQS queues were locked in endless retrying loops, Lambda functions crashed constantly under load, and database write locks occurred during high-throughput Amazon SP-API data fetches. Amzigo was forced to manually monitor system logs, babysit server processes 24/7, and handle frequent crash reports from frustrated active users. Furthermore, the legacy agency neglected to build an administrative dashboard, leaving Amzigo with zero visibility into user logs, data freshness, or scraper health, while locking them into high-cost, expensive third-party web scraper subscriptions.
- Bubble.io Visual Database
- Unmanaged AWS Lambda Functions
- Endless AWS SQS Retry Loops
- Expensive Third-Party Data Scrapers
- No Admin Dashboards or User Logs
- Next.js Server-Side Rendered (SSR) Landing
- Interactive React.js Seller Dashboard
- Node.js API + Agenda.js Background Queue
- PostgreSQL & MongoDB Database Layer
- In-House Custom scrapers & Full Admin Panel
Phase 1: Stabilization & Private Scraping Infrastructure
Our specialized engineering pod prioritized immediate code stabilization to stop operational system crashes. Our specialized Amazon SP API development team audited and patched database connection pools, fixed SQS visibility timeouts, and implemented robust exponential backoff retries within the AWS Lambda configurations. Within days, this stabilization terminated constant data synchronization drops, freeing the client from monitoring email alert logs.
Next, we developed a highly efficient, proprietary in-house scraping framework to cut out expensive monthly third-party API subscriptions. Our custom web scraping tools bypass external rate limits, retrieve inventory status and rank tracking directly with high data accuracy, and save Amzigo thousands of dollars in monthly operating costs, significantly increasing their gross SaaS margins.
Phase 2: Complete Re-Architecture to Next.js, React & Node.js
We rebuilt the entire SaaS platform from the ground up inside 10 weeks to guarantee modern horizontal scaling. Our full-stack custom software engineering team divided the application into dedicated, focused architectural planes:
- Public Marketing Site: Developed in Next.js leveraging Server-Side Rendering (SSR) to achieve perfect SEO scoring and sub-second page loads.
- Seller Operations Dashboard: Built in React.js utilizing TailwindCSS and D3.js, rendering interactive charting for sales velocity, profit tracking, and automated email campaign configurations.
- Backend Core & Agenda: Engineered on Node.js using Agenda.js jobs scheduler for background automation, managing complex review requests and Amazon SP-API data polling without bottlenecking active client requests.
- Administrative Command Center: Engineered a robust internal admin dashboard, granting the client absolute control to monitor scraper cycles, view system-wide logs, analyze user interactions, and debug API connections in real-time.
Quantified Business Outcomes
Our technical intervention transformed Amzigo from an unstable product into an institutional platform capable of scaling safely to thousands of active e-commerce brands.
| Performance Metric | Legacy Bubble + AWS Stack | Parallel Loop Rebuilt Stack |
| Data Synchronization | 24-Hour Latency | 15-Minute Real-Time Refresh |
| Active Dashboard Load Time | 12.0 Seconds | 1.2 Seconds (Sub-second static assets) |
| Third-Party Scraper API Spend | High Monthly Cost | $0.00 (In-House Custom Scrapers) |
| Monthly User Churn | 8.0% Churn Rate | 2.1% (Increased Trust & Stability) |
Technical Deep-Dive: Frequently Asked Questions
How did the custom scrapers reduce monthly B2B SaaS operating costs?
Our engineering team built dedicated scraping agents in Node.js, running directly on private server blocks. This eliminated dependencies on high-cost third-party API scraper services, reducing scraper fee margins to zero dollars, while increasing fetching speed and parsing accuracy for product rankings and review counts.
Why did you select Agenda.js instead of standard Cron or Bull Queue?
Agenda.js provides highly readable, MongoDB-backed database job scheduling that is extremely light on memory utilization. Because e-commerce sync requires both structured recurring cycles (e.g., fetch Amazon SP-API data every 15 minutes) and singular event delays (e.g., send automated review requests 7 days post-delivery), Agenda allowed us to orchestrate both easily inside a single unified Node.js backend.
How was multi-tenant data isolation achieved during migration?
We engineered a robust database layout in PostgreSQL, utilizing advanced row-level security (RLS) policies. Every incoming API transaction requires active multi-tenant validation, guaranteeing that user seller keys, metrics, and customer email records are safely partitioned and isolated at all times.